Two main families of data models and how they affect your engineering - AI/ML communication

This post tries to explain, using an enormous simplification, the difference between two leading families of data models that are in use in modern data workflows, especially in the context of feeding ML/AI - relational and document/object representations.
Note: By data model, this article means the structure of the data records at various stages of their lifecycle. This is in contrast to an ML/AI model - an artefact of applying a learning algorithm to data.
Why this post?
Modelling real-world data for computers to understand and operate on resembles unrooting the garden plants and putting them in the pot. On the one hand, these are still the same beloved specimen - which you can now move around, sell, replant in a hydroponic farm or arrange at your home to enjoy. On the other hand - it is very different - its roots might have been squashed, some leaves or flowers fell off, it is no longer part of the garden ecosystem. Modelling data is very similar - we need to look at what is essential for a given task, measure it against the available technology and on to the shovel... or extraction tools. The motivation for this post comes from a particular experience of mine. Several years ago, I witnessed a long, heated feud between two data-heavy departments. The teams opted for different representations (or plant types) and tried to push their preference as the more general, cross-departmental solution. Putting the political and human issues aside, their respective leaders, engineers with dozens of years of experience, could not understand one another's choice. They would cherry-pick specifications and architectural patterns, delve into limitations of particular processing frameworks, engage the teams with prolonged meetings with various stakeholders trying to resolve the conflict and throw (meaningless) benchmarks at each other. It took months until the teams realised both representations were necessary, and their differences came from the interfaces and respective groups' use cases. With the benefit of hindsight - as is usually the case in similar situations - this could have been resolved with a touch of mediation and a high-level technical summary. As an observer, I lacked the tools to help at the time - and this post is an attempt to rectify that.
Relational / Tabular
When thinking about databases, what usually comes to mind are Relational Database Management Systems that use the SQL language to ingest and deliver the data. These proved to be some of the most resilient and valuable systems ever produced, being at the core of the data world for over 40 years. Data is formed into relationships or tables representing entities and interactions between them. Each relation represents objects of one type. There are canonical ways (normal forms) to standardise and optimise access to the records. For example, to represent patients getting treated in a particular hospital, we may end up with the following:
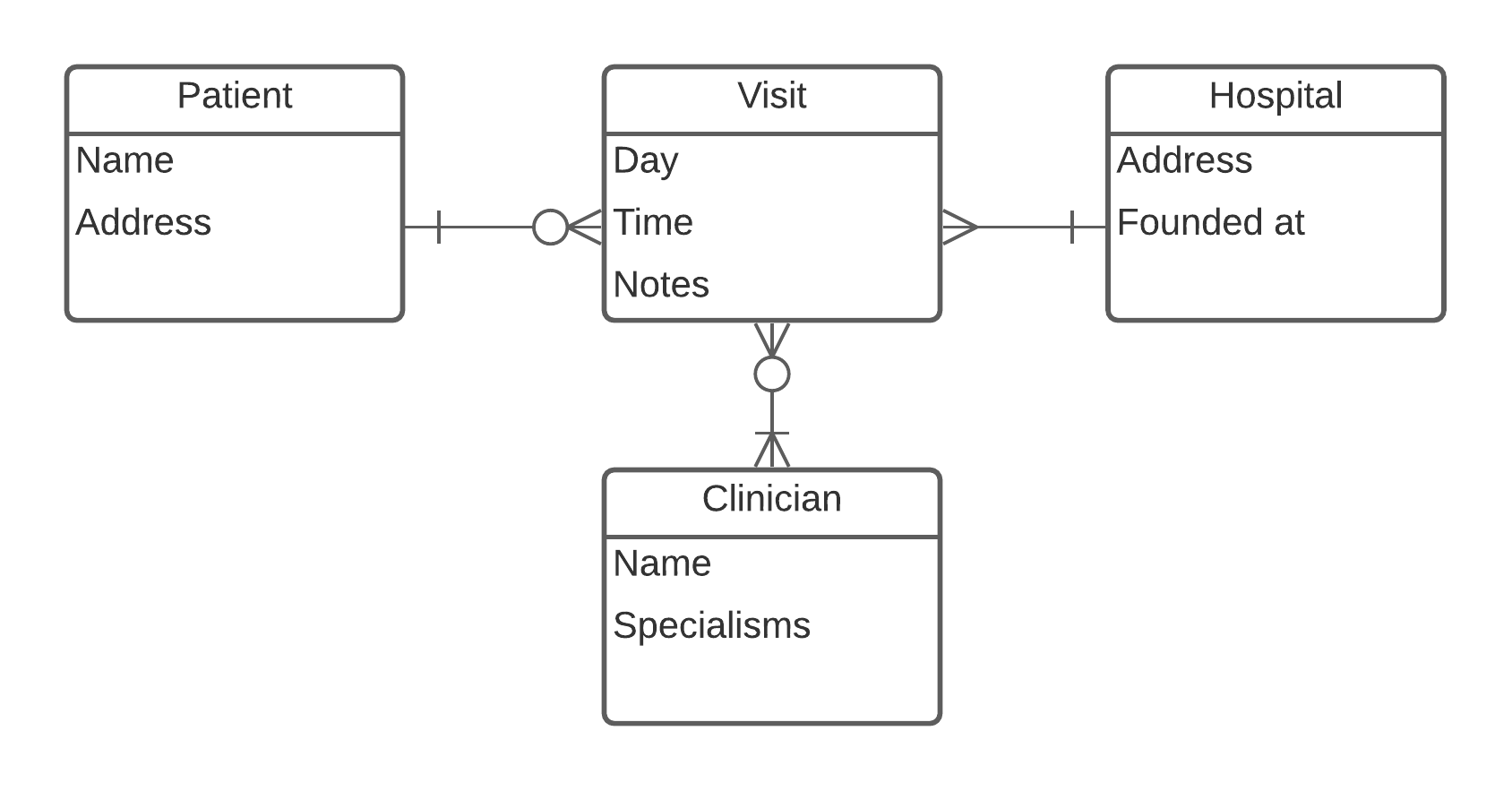 Predating RDBMS are tables, used at least in the times of ancient Egypt. Plain, two dimensional lists of observations they allow for quick, intuitive referencing. With their modern incarnation - spreadsheets, and with related storage types (like CSV) they belong to the same relational / tabular family of models.
These methods are powerful:
* Flexible analytics from an arbitrary access point * Use of optimised data types - improvements for storage and access * Per column compression * Extensible indexing mechanism * Easy to comprehend, human-readable records.
Drawbacks include:
* Considerable modelling effort * Rigidness - challenging to adjust the model; small changes in relations result in non-trivial schema adjustments * Dealing with one-to-many and many-to-many relationships are not intuitively interpretable * Infrastructure required for joining the data
Predating RDBMS are tables, used at least in the times of ancient Egypt. Plain, two dimensional lists of observations they allow for quick, intuitive referencing. With their modern incarnation - spreadsheets, and with related storage types (like CSV) they belong to the same relational / tabular family of models.
These methods are powerful:
* Flexible analytics from an arbitrary access point * Use of optimised data types - improvements for storage and access * Per column compression * Extensible indexing mechanism * Easy to comprehend, human-readable records.
Drawbacks include:
* Considerable modelling effort * Rigidness - challenging to adjust the model; small changes in relations result in non-trivial schema adjustments * Dealing with one-to-many and many-to-many relationships are not intuitively interpretable * Infrastructure required for joining the data
Document / Object
The Big data era popularised the concept of denormalisation. In short, instead of keeping the records in dedicated tables and joining them whenever the linking was required, we would merge the relevant records into higher-level objects. For example, a Patient would no longer contain the reference to a hospital visit; instead, all this information would be nested in a single field.

There were several reasons for this approach: * Scale - it was impossible to store the volume on a single machine (and at the time, most SQL databases could not be distributed). * Ability to decouple the data from the RDBMS systems. Data can be stored, viewed, and processed as a collection of files without building and maintaining active database servers. * Familiarity and ease-of-use of object-oriented programming - instead of relying on a language meant for many-records analytics and difficult to debug - allowed for a quick traversal of all the fields required for a particular task. This was paired with the popularity of this model in web development, embodied in JSON format. In the end, in addition to staple Big data key-value and column-family solutions, which required object serialisation, dedicated document-oriented databases gained popularity. The object-oriented model has its drawbacks: * Lack of query flexibility - the storage layer is tightly coupled with the intended usage * The explosion of size - the same data needs to be stored in multiple records * Duplication - when another view of the data is necessary - a new set needs to be built and maintained * Limited support for joining different object types * Modelling many-to-many relationships is difficult
Dataframes - or where it gets interesting
Dataframe is the cornerstone of scientific and numerical computing. With powerful, lightweight libraries and frameworks (such as Pandas or Spark) coupled with visualisation capabilities, they are often a go-to approach for quick and dirty pipelines. Because of their extensibility and flexibility, they occasionally become part of core production systems - with mixed results. More importantly, however, they are native to many ML/AI learning libraries, becoming a necessary interface, often (intentionally or not) spilling to the earlier phases of the data processing. At the first look - they belong firmly in the relational model realm. However, they often allow embedding more complex objects in the overall structure. Hence, they provide a bridge between two worlds, mixing the strengths and drawbacks of both approaches - for a limited set of use cases where it can be applied.
A note on graphs
While this article paints the model landscape in very bold strokes, graph databases built for quick traversal of entity and relationship types become an important part of the landscape, especially in highly-hierarchical, messy and quickly evolving environments. They can be viewed as a lighter, more flexible version of the relational model tuned for pattern matching.
What AI/ML needs?
Most ML/AI model building relies on features being supplied as a table - a row per data point. Some built-in datastore-specific libraries break the convention (e.g. Neo4j DS or MindsDB by coupling learning with storage - these are, however, exceptions. There are some added complexities around tensor-based deep learning models where features (e.g. images or blocks of text) need to be structured in uniform batches. To sum up building models requires a table/data frame (e.g. a CSV), with further particularly-formatted files when applicable, e.g. in the image deep learning setting. Right, so what data model should I be using, I hear you ask. If only there was a straightforward answer. There are plenty of factors to consider: * The eventual use case * The size and complexity of the data * Which parts of the original data do you need * Available infrastructure * The skills in the team * The original data format * The required analytics As a very rough guide, these several rules of thumb that helped us out in the past: * Use immutable/flat files whenever possible to minimise infrastructure and maintenance costs * Keep the extraction as close to the original as you can * Tune the analytics technology to the skillset available * It is easier to convert from relational to object representation than the other way around * Object model is much easier to scale * It is easier to test object representation and transformations * The end step is nearly always a much smaller table of features - getting it is in practice similarly difficult for both models.
The case of Arachne.ai
Arachne.ai is a product for quick, controlled acquisition and management of biomedical datasets to speed up building AI/ML solutions in pharma, Biotech and Medtech spaces. The goal is to allow a simple low-code definition to drive repeated acquisition and extraction of relevant biomedical facts from an arbitrary dataset. Then to keep those up to date, perform automated quality control and provide tools for ML/AI research to use the controlled data with minimal overhead. Optional plugins and tools help with reconciliation, merging and moving the data to dedicated storage - for example, an API-ready knowledge graph or a search-focused text cluster.
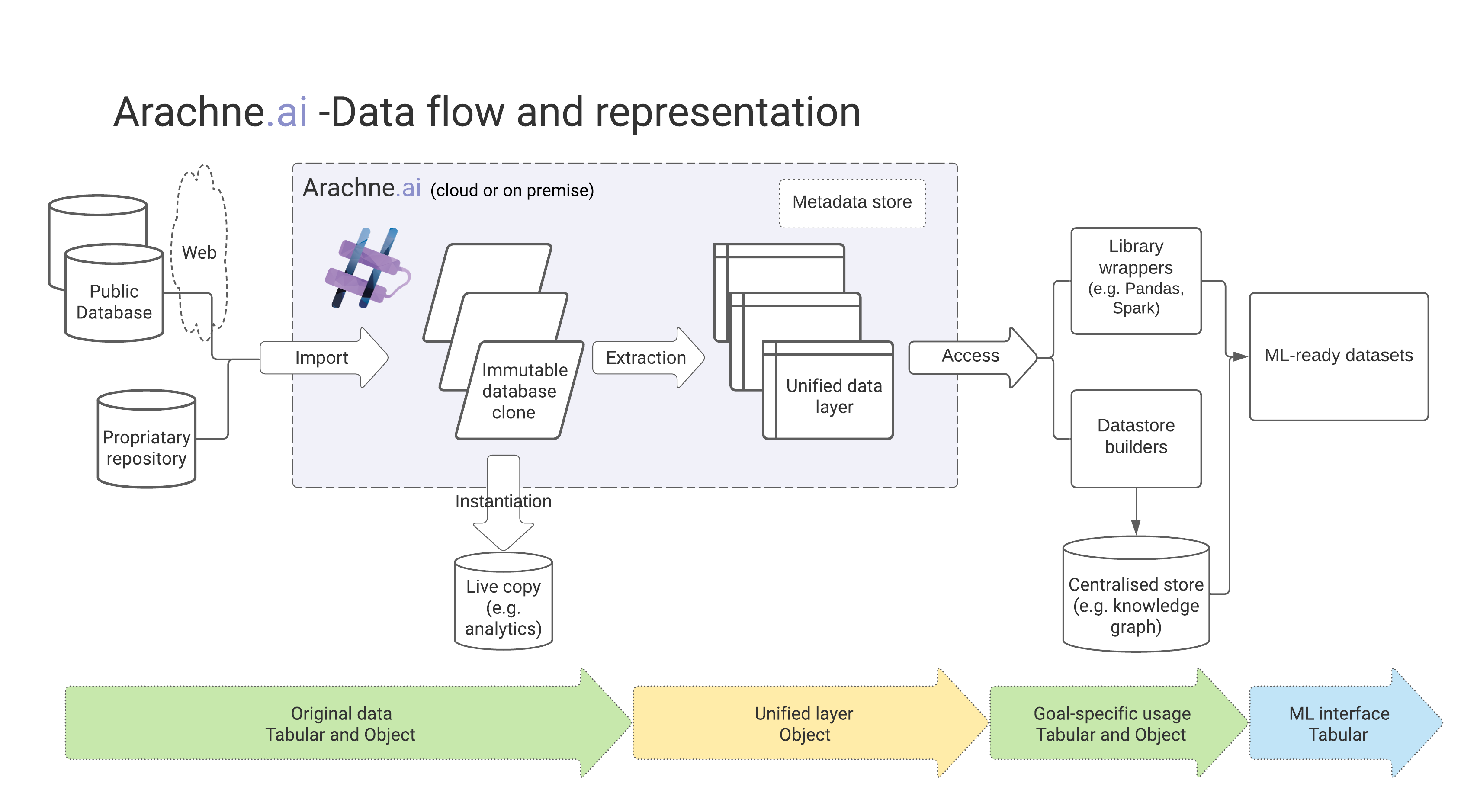 The scale and diversity of datasets available publicly are astounding, both in terms of contents and formats - take a look at BiŌkeanós. From textual through various files and database systems, images, a plethora of common and specialised bioinformatics file formats, ontologies and -omics to scraping results. This is further complicated by company-specific proprietary datasets, with various degrees of FAIR-ness. We needed to minimise storage and maintenance issues and allow the system to scale in a cloud-native way. To achieve that, we rely on the immutable original files acquisition, then a unification to object model for analytics and standardised processing. We supply lightweight data frame wrappers (Spark, pandas) for further processing and passing to the model building stage. When necessary, the original format (now verified, versioned and controlled) can be accessed as well.
The scale and diversity of datasets available publicly are astounding, both in terms of contents and formats - take a look at BiŌkeanós. From textual through various files and database systems, images, a plethora of common and specialised bioinformatics file formats, ontologies and -omics to scraping results. This is further complicated by company-specific proprietary datasets, with various degrees of FAIR-ness. We needed to minimise storage and maintenance issues and allow the system to scale in a cloud-native way. To achieve that, we rely on the immutable original files acquisition, then a unification to object model for analytics and standardised processing. We supply lightweight data frame wrappers (Spark, pandas) for further processing and passing to the model building stage. When necessary, the original format (now verified, versioned and controlled) can be accessed as well.
Summary
This article roughly outlined the two primary data modelling families used in the modern data workflows in the context of ML/AI - the relational and object-oriented representation. Neither is perfect, and the usage of each must be tuned to your use case.
By subscribing, you agree to our Privacy policy.